layout: post
title: tidyverse
author: CY
tags: [R]
categories: [R]
share: false
image:
background: triangular.png
tidyverse introduction
The tidyverse is an opinionated collection of R packagesdesigned for data science. All packages share an underlying philosophy and common APIs.
大部分数据分析任务,通常有一些固定的操作,操作对应的命令和library也是相对固定的:
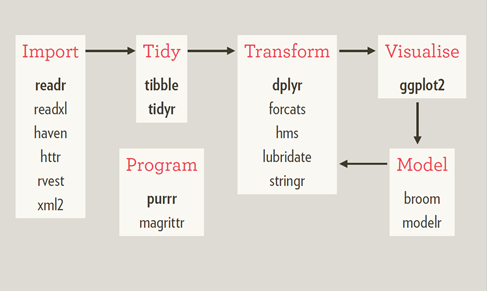
首先,导入数据→整理数据,然后进入:转换数据→数据图像化→建立模型这三者的循环中,同时需要一些操作让我们的代码更简洁。在这个过程中,我们经常会用到相应的很多library,悲剧的是我们经常会因为忘记载入相应的包而出现一系列的报错。是时候拿出大杀器tidyverse了。
tidyverse包一言以蔽之就是:Tidyverse是一个集成的系统包,里面包含了众多用作数据处理分析的library,并且持续更新中。载入这个包,你就可以高枕无忧了,以上所有命令随意用。哈哈哈哈
tidyverse usage
install.packages("tidyverse")
library(tidyverse)
tidyverse including packages:
- Load the core tidyverse packages:
- Working with specific types of vectors:
- Importing other types of data:
- Modelling