Mendelian randomization
今天journal club的paper是用孟德尔随机化研究方法研究与pancreatic cancer相关的risk factor。
Definition
In epidemiology, Mendelian randomization (MR) is a method of using measured variation in genes of known function to examine the causal effect of a modifiable exposure on disease in observational studies.
The design was first proposed in 1986 and subsequently described by Gray and Wheatley as a method for obtaining unbiased estimates of the effects of a putative causal variable without conducting a traditional randomized trial.
The design has a powerful control for reverse causation and confounding which otherwise bedevil epidemiological studies.
以上是来自维基百科的定义。由于传统的观察性研究容易出现偏差,如反向因果关系(指暴露和结局的时间顺序颠倒)和残留的混杂因素,这限制了我们正确理解暴露与结局之间的相关性。孟德尔随机化设计通过引入计量经济学中的工具变量(instrumental variable,Ⅳ)的概念,将基因变异作为待研究暴露因素的工具变量,为解决上述问题提供了有效的途径。
设计原理
1986年,Katan首先提出:不同基因型决定不同的中间表型,若该表型代表个体的暴露特征,用基因型和疾病的关联效应就能够模拟暴露因素对疾病的作用。由于等位基因在配子形成时遵循随机分配原则,基因型-疾病的效应估计值不会被传统流行病学研究中的混杂因素和反向因果关联所歪曲,这恰恰是孟德尔随机化设计的精髓。
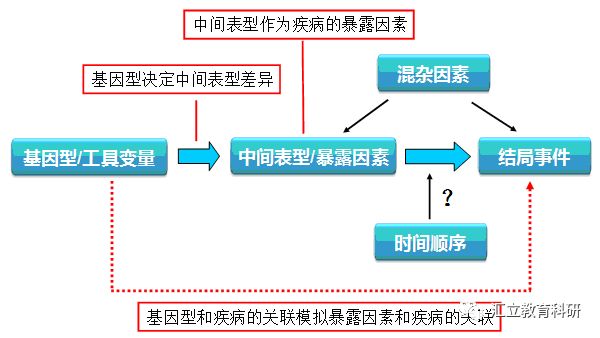
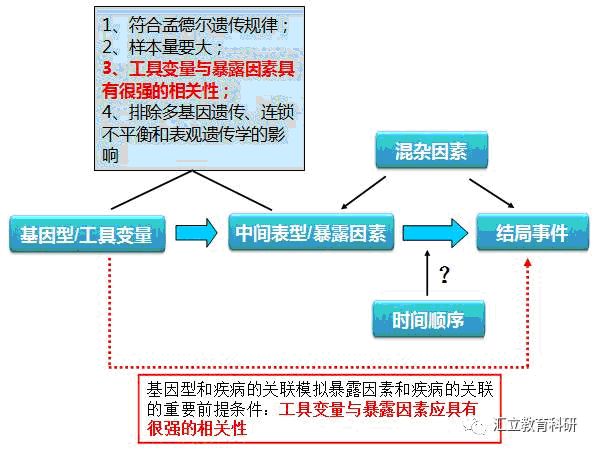
使用前提
MR遵循“亲代等位基因随机分配给子代”的孟德尔遗传定律,选择合适的“基因变异”作为工具变量,指代无法测量的待研究暴露因素,通过测量遗传变异与暴露因素、遗传变异与疾病结局之间的关联,进而推断暴露因素与疾病结局之间的关联。设计MR需要满足一定的条件(如图示)。
工具变量
MR设计的最关键步骤是寻找合适的遗传变异作为工具变量。研究最多的遗传变异类型是SNP,事实上任何一种变异类型都可以作为工具变量,比如copy number variants。
建立遗传工具变量的方法一般包括两种:
① 选择与目标暴露因素有直接强关联(robust)的遗传变异,如与酒精代谢直接相关的乙醇脱氢酶1b(ADH1B)基因变异。
② 从GWAS数据库获得遗传工具变量,目前全球GWAS研究目录显示超过1万条有潜在功能学意义的SNP,其中4 000个以上的SNPs与相应表型有唯一关联,可以从中筛选合适的工具变量。
可靠性评价
1.敏感度分析(sensitivity analysis):MR分析中如果出现非特异性的SNPs作为工具变量(即SNPs与目标暴露因素有关,同时与其他暴露因素也有关联),此时可以使用敏感度分析来确定其存在可以造成多大的影响。如果剔除非特异性SNPs以后,其他遗传工具变量和结局之间的关联结果依然有统计学意义,则说明暴露因素与结局的因果关联证据更强。
2.MR-Egger回归分析:如果采用多个SNPs作为工具变量进行因果推断,很难避免基因多效性(pleiotropy)带来的偏倚,一方面可以使用直观的漏斗图的对称性来判断小样本研究是否存在偏倚,同时也可以使用MR-Egger回归分析的方法来评价基因多效性带来的偏倚,MR-Egger回归直线的斜率可以估计定向多效性(directional pleiotropy)的大小。
研究局限性
随着组学技术的发展,工具变量的丰富,交叉学科为MR研究复杂暴露因素与疾病结局因果关联提供了广阔的基础。但是MR研究仍存在一定的局限性:
① 难以发现合适的遗传工具变量:并非所有SNPs都适宜作为工具变量,基于GWAS的GRS也并非完美,很难控制弱工具变量偏倚。
② 把握度较低:只有通过扩大样本量获得足够的把握度,比如使用仅占1%效应的遗传工具探讨暴露和疾病之间的关联,至少需要9 500对以上的病例和对照样本才能有80%的把握度获得增加50%(OR=1.5)的生物学效应(每个标准差水平)。
③ Beavis效应:基于GWAS数据的MR研究可能会高估了遗传和暴露之间的关联,因为SNPs与混杂因素之间可能有潜在的关联。
④ 合理的生物学解释:MR研究可能与观察性研究结论相反,需要进一步研究验证。
BMI作为U型数据分布作为连续变量分析的缺点
一哥们提出,BMI与死亡率的关系为U型(在合适的BMI范围内,死亡率最低,BMI过高或者过低都会增加死亡率率)。那么在研究中BMI是否适合作为连续性变量,而不是分类变量?因为如果把BMI作为连续变量的话,是不符合线性这个前提条件?
这个。。。待我以后来补充