Survival analysis --R code
Surv:用于创建生存数据对象
survfit:创建KM生存曲线或是Cox调整生存曲线
survdiff:用于不同组的统计检验 (非参数法)
coxph:构建COX回归模型 (半参数法)
cox.zph:检验PH假设是否成立 (半参数法)
survreg:构建参数模型 (参数法)
准备工作
#安装R包
#install.packages(c("survival", "survminer"))
#加载R包
library(survival)
library(survminer)
#survival包里包含的数据集
data(package="survival")
#以肺癌数据为例,显示数据前六行
head(lung)
## inst time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
## 1 3 306 2 74 1 1 90 100 1175 NA
## 2 3 455 2 68 1 0 90 90 1225 15
## 3 3 1010 1 56 1 0 90 90 NA 15
## 4 5 210 2 57 1 1 90 60 1150 11
## 5 1 883 2 60 1 0 100 90 NA 0
## 6 12 1022 1 74 1 1 50 80 513 0
#查看肺癌数据详细说明
?lung
#inst: Institution code
#time: Survival time in days
#status: censoring status 1=censored, 2=dead
#age: Age in years
#sex: Male=1 Female=2
#ph.ecog: ECOG performance score (0=good 5=dead)
#ph.karno: Karnofsky performance score (bad=0-good=100) rated by physician
#pat.karno: Karnofsky performance score as rated by patient
#meal.cal: Calories consumed at meals
#wt.loss: Weight loss in last six months
建立生存分析
#创建生存数据对象
surv_obj <- with(lung, Surv(time, status))
#用survfit()估计KM生存曲线, 用数据集中所有患者作为分析对象
fit1 <- survfit(surv_obj ~ 1)
#显示寿命表
summary1 <- surv_summary(fit1)
head(summary1)
## time n.risk n.event n.censor surv std.err upper lower
## 1 5 228 1 0 0.9956140 0.004395615 1.0000000 0.9870734
## 2 11 227 3 0 0.9824561 0.008849904 0.9996460 0.9655619
## 3 12 224 1 0 0.9780702 0.009916654 0.9972662 0.9592437
## 4 13 223 2 0 0.9692982 0.011786516 0.9919508 0.9471630
## 5 15 221 1 0 0.9649123 0.012628921 0.9890941 0.9413217
## 6 26 220 1 0 0.9605263 0.013425540 0.9861367 0.9355811
#中位生存期及95%置信区间
#中位生存期:当累积生存率为0.5时所对应的生存时间,表示有且只有50%的个体可以活过这个时间.
fit1
## Call: survfit(formula = surv_obj ~ 1)
##
## n events median 0.95LCL 0.95UCL
## 228 165 310 285 363
##25%, 50%, 75%生存期
quantile(fit1, probs=c(0.25, 0.5, 0.75), conf.int=FALSE)
## 25 50 75
## 170 310 550
#50天和100天生存状况
summary(fit1, times=c(200, 400))
## Call: survfit(formula = surv_obj ~ 1)
##
## time n.risk n.event survival std.err lower 95% CI upper 95% CI
## 200 144 72 0.680 0.0311 0.622 0.744
## 400 57 54 0.377 0.0358 0.313 0.454
不同因子生存曲线的比较
例如我们想比较男性和女性肺癌患者生存曲线的差别
#用survfit()估计KM生存曲线, 方程右边以性别为区分,分别估计男性和女性的生存曲线
fit2 <- survfit(surv_obj ~ sex, data = lung)
#分别显示男性和女性的寿命表
summary2 <- surv_summary(fit2)
head(summary2)
## time n.risk n.event n.censor surv std.err upper lower
## 1 11 138 3 0 0.9782609 0.01268978 1.0000000 0.9542301
## 2 12 135 1 0 0.9710145 0.01470747 0.9994124 0.9434235
## 3 13 134 2 0 0.9565217 0.01814885 0.9911586 0.9230952
## 4 15 132 1 0 0.9492754 0.01967768 0.9866017 0.9133612
## 5 26 131 1 0 0.9420290 0.02111708 0.9818365 0.9038355
## 6 30 130 1 0 0.9347826 0.02248469 0.9768989 0.8944820
## strata sex
## 1 sex=1 1
## 2 sex=1 1
## 3 sex=1 1
## 4 sex=1 1
## 5 sex=1 1
## 6 sex=1 1
#分别显示男性和女性的中位生存期及95%置信区间
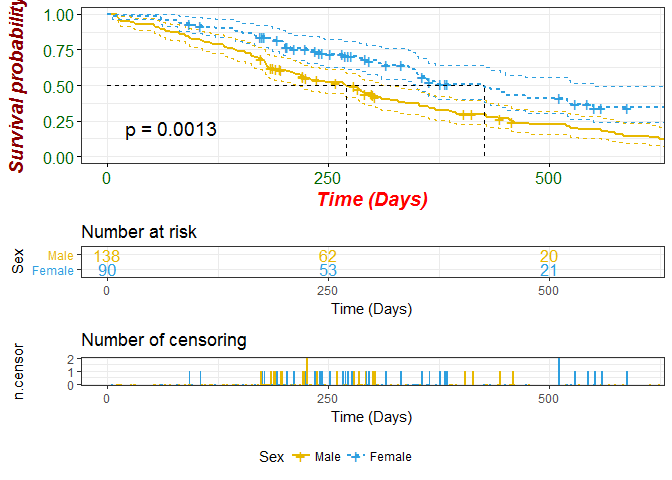
fit2
## Call: survfit(formula = surv_obj ~ sex, data = lung)
##
## n events median 0.95LCL 0.95UCL
## sex=1 138 112 270 212 310
## sex=2 90 53 426 348 550
#用lag-rank test检验不同组生存曲线的差异
#survdiff()函数最后一个参数为rho,用于指定检验的类型
#rho=0(默认),进行log-rank检验或Mantel−Haenszelχ2检验,比较各组期望频数和实际观察数。如果两组间的差异水平太大,χ2会较大而P值较小,表示生存曲线有统计学差异.
#当rho=1时,进行Gehan-Wilcoxon的Peto校正检验,该检验赋予早期终点事件较大的权重
surv_diff <- survdiff(surv_obj ~ sex, data = lung)
surv_diff
## Call:
## survdiff(formula = surv_obj ~ sex, data = lung)
##
## N Observed Expected (O-E)^2/E (O-E)^2/V
## sex=1 138 112 91.6 4.55 10.3
## sex=2 90 53 73.4 5.68 10.3
##
## Chisq= 10.3 on 1 degrees of freedom, p= 0.00131
生存曲线可视化
绘制两条生存曲线
ggsurv <- ggsurvplot(fit2, #survfit object with calculated statistics.
data = lung, #data used to fit survival curves.
main = "Survival curve", #add title
xlab = "Time (Days)", #change the x axis label.
font.main = c(16, "bold", "darkblue"), #change title font size, style and color
font.x = c(14, "bold.italic", "red"), #change x axis label font size, style and color
font.y = c(14, "bold.italic", "darkred"), #change y axis font size, style and color
font.tickslab = c(12, "plain", "darkgreen"), #change ticks label font size, style and color
legend = "bottom", #change legend position
#legend = c(0.2, 0.2), #Specify legend position by its coordinates
legend.title = "Sex", #change legend title
legend.labs = c("Male", "Female"), #change legend labels
size = 1, #change line size
linetype = "strata", #change line type by groups (i.e. "strata")
break.time.by = 250, #break X axis in time intervals by 250
#xlim = c(0, 600)), #shorten the survival curves
palette = c("#E7B800", "#2E9FDF"), #custom color palette
#palette = "Dark2", #Use brewer color palette "Dark2"
#palette = "grey", #Use grey palette
conf.int = TRUE, #Add confidence interval
conf.int.style = "step", #customize style of confidence intervals
pval = TRUE, #Add p-value of the Log-Rank test comparing the groups
surv.median.line = "hv", #add horizontal/vertical line at median survival.
risk.table = TRUE, #Add risk table
#risk.table = "absolute/percentage/abs_pct",
#to show absolute number, percentage of subjects, and both at risk by time, respectively.
risk.table.col = "strata", #Change risk table color by groups
risk.table.y.text.col = TRUE, #colour risk table text annotations by strata
#risk.table.y.text = FALSE, #show bars instead of names in text annotations in legend of risk table
risk.table.height = 0.25, #the height of the risk table. Useful when you have multiple groups
ncensor.plot = TRUE, # plot the number of censored subjects at time t
ncensor.plot.height = 0.25,
ggtheme = theme_bw(), #customize plot and risk table with a theme.
xlim = c(0, 600) #Change x axis limits (xlim)
)
ggsurv
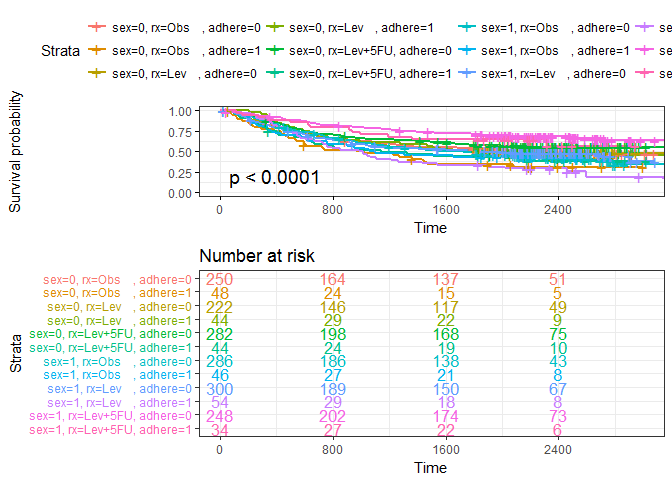
绘制多条生存曲线
fit3 <- survfit(Surv(time, status) ~ sex + rx + adhere, data = colon )
ggsurvplot(fit3,
pval = TRUE, #Add p-value
break.time.by = 800, #break time axis by 800
risk.table = TRUE, #add risk table
risk.table.col = "strata", #Change risk table color by groups
risk.table.height = 0.5, #the height of the risk table. Useful when you have multiple groups
ggtheme = theme_bw() #change plot theme
#legend.labs = c("A", "B", "C", "D", "E", "F") #Change legend labels
)
Cox回归
单因素COX回归
covariates <- c("age", "sex", "ph.karno", "ph.ecog", "meal.cal", "wt.loss")
univ_formulas <- sapply(covariates,
function(x) as.formula(paste('Surv(time, status)~', x)))
univ_models <- lapply( univ_formulas, function(x){coxph(x, data = lung)})
# Extract results
univ_results <- lapply(univ_models,
function(x){
x <- summary(x)
p.value<-signif(x$wald["pvalue"], digits=2)
wald.test<-signif(x$wald["test"], digits=2)
beta<-signif(x$coef[1], digits=2);#coeficient beta
HR <-signif(x$coef[2], digits=2);#exp(beta)
HR.confint.lower <- signif(x$conf.int[,"lower .95"], 2)
HR.confint.upper <- signif(x$conf.int[,"upper .95"],2)
HR <- paste0(HR, " (",
HR.confint.lower, "-", HR.confint.upper, ")")
res<-c(beta, HR, wald.test, p.value)
names(res)<-c("beta", "HR (95% CI for HR)", "wald.test",
"p.value")
return(res)
#return(exp(cbind(coef(x),confint(x))))
})
results <- t(as.data.frame(univ_results, check.names = FALSE))
as.data.frame(results)
## beta HR (95% CI for HR) wald.test p.value
## age 0.019 1 (1-1) 4.1 0.042
## sex -0.53 0.59 (0.42-0.82) 10 0.0015
## ph.karno -0.016 0.98 (0.97-1) 7.9 0.005
## ph.ecog 0.48 1.6 (1.3-2) 18 2.7e-05
## meal.cal -0.00012 1 (1-1) 0.29 0.59
## wt.loss 0.0013 1 (0.99-1) 0.05 0.83
多因素COX回归
多个自变量是如何共同影响因变量
cox_model <- coxph(Surv(time, status) ~ age + sex + ph.ecog + ph.karno, data = lung)
summary(cox_model)
## Call:
## coxph(formula = Surv(time, status) ~ age + sex + ph.ecog + ph.karno,
## data = lung)
##
## n= 226, number of events= 163
## (2 observations deleted due to missingness)
##
## coef exp(coef) se(coef) z Pr(>|z|)
## age 0.012868 1.012951 0.009404 1.368 0.171226
## sex -0.572802 0.563943 0.169222 -3.385 0.000712 ***
## ph.ecog 0.633077 1.883397 0.176034 3.596 0.000323 ***
## ph.karno 0.012558 1.012637 0.009514 1.320 0.186842
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## age 1.0130 0.9872 0.9945 1.0318
## sex 0.5639 1.7732 0.4048 0.7857
## ph.ecog 1.8834 0.5310 1.3338 2.6594
## ph.karno 1.0126 0.9875 0.9939 1.0317
##
## Concordance= 0.632 (se = 0.026 )
## Rsquare= 0.129 (max possible= 0.999 )
## Likelihood ratio test= 31.27 on 4 df, p=2.695e-06
## Wald test = 30.61 on 4 df, p=3.676e-06
## Score (logrank) test = 31.06 on 4 df, p=2.974e-06
COX回归结果解释
1. z结果是wald检验的结果,z = coef/se(coef),用于检验回归系数是否显著区别于0
2. 回归系数(coef)
3. 风险率(hazard ratio, HR): HR = exp(coef), 衡量协变量影响的程度
4. 风险比的95%置信区间
5. 对模型的整体分析,即评价模型是否有意义的三种检验(Likelihood ratio test, Wald test, Score (logrank) test)
COX模型等比性检验
方法一:通过图形展示,对纵轴和横轴分别取对数,绘制不同自变量水平下的生存曲线。如果两条曲线平行,则符合比例风险假定.
方法二:利用cox.zph函数进行检验
cox.zph(cox_model)
## rho chisq p
## age 0.0168 0.0502 0.8227
## sex 0.0881 1.2539 0.2628
## ph.ecog 0.0600 0.5122 0.4742
## ph.karno 0.1843 4.4660 0.0346
## GLOBAL NA 8.0414 0.0901
#检验结果中ph.karno具有显著性(p<0.05),即这一自变量不符合“等比性”要求,这一回归模型不准确
根据检验结果调整模型,将不可比的自变量进行分层, 也就是说排除混杂因素的影响,分析研究因素的影响
cox_model1 <- coxph(Surv(time, status) ~ age + sex + ph.ecog + strata(ph.karno), data = lung)
summary(cox_model1)
## Call:
## coxph(formula = Surv(time, status) ~ age + sex + ph.ecog + strata(ph.karno),
## data = lung)
##
## n= 226, number of events= 163
## (2 observations deleted due to missingness)
##
## coef exp(coef) se(coef) z Pr(>|z|)
## age 0.014807 1.014918 0.009651 1.534 0.124972
## sex -0.591683 0.553395 0.173049 -3.419 0.000628 ***
## ph.ecog 0.483879 1.622356 0.196558 2.462 0.013825 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## age 1.0149 0.9853 0.9959 1.0343
## sex 0.5534 1.8070 0.3942 0.7768
## ph.ecog 1.6224 0.6164 1.1037 2.3848
##
## Concordance= 0.601 (se = 0.054 )
## Rsquare= 0.085 (max possible= 0.986 )
## Likelihood ratio test= 19.99 on 3 df, p=0.0001708
## Wald test = 19.14 on 3 df, p=0.0002557
## Score (logrank) test = 19.57 on 3 df, p=0.0002083
再次检验模型
cox.zph(cox_model1)
## rho chisq p
## age 0.0454 0.363 0.547
## sex 0.0919 1.289 0.256
## ph.ecog 0.0358 0.184 0.668
## GLOBAL NA 1.958 0.581
#哈哈哈,bingo~